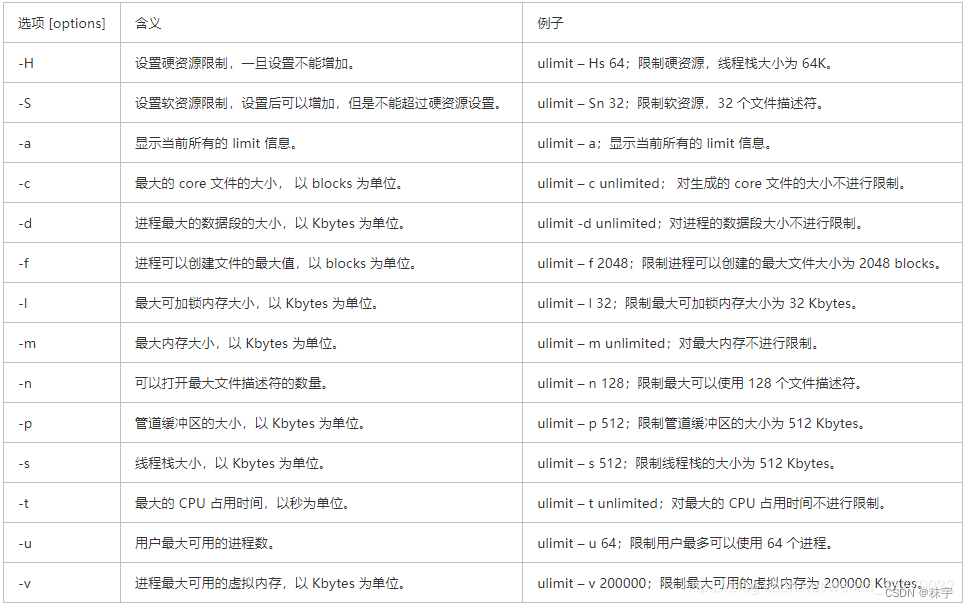
目录
一、前言
二、完成情况
2.1 生成速度模型剖面图
2.2 吴恩达机器学习系列课程
2.2.1 介绍
2.2.1.1 机器学习
2.2.1.2 监督学习
2.2.1.3 无监督学习
2.2.2 单变量线性回归
2.2.2.1 模型表示
2.2.2.2 代价函数
2.2.2.3 梯度下降
2.2.2.4 梯度下降的线性回归
2.2.3 线性代数回顾
2.2.3.1 向量和矩阵
2.2.3.2 加法和标量乘法
2.2.3.3 矩阵向量乘法
2.2.3.4 矩阵乘法与性质
2.2.3.5 逆与转置
2.2.4 多变量线性回归
2.2.4.1 多维特征
2.2.4.2 多变量梯度下降
2.2.4.3 特征缩放
2.2.4.4 学习率
2.2.4.5 特征和多项式回归
2.2.4.6 正规方程
三、下周计划
3.1 存在的问题
3.2 计划
一、前言
在上周,尝试添加可变形卷积v4、完成了Latex的下载与安装。
本周,在上周的基础上继续进行思考、学习吴恩达机器学习的系列视频以及Latex论文编辑的格式。另外,思考论文的大概标题与内容。
二、完成情况
2.1 生成速度模型剖面图
在回顾之前看过的论文时注意到有研究人员在论文中使用到了“速度模型剖面图”作为实验结果进行对比分析,感觉也很直观看出方法之间的差距。因此,学习了如何生成“速度模型剖面图”。
该问题转换为:读取速度模型某一列的像素值,使用折线图绘制数据变化情况。具体实现代码与图片如下所示,其中的一些细节还需调整:
import matplotlib.pyplot as plt
def plot_velocity_image(num, output, target, test_result_dir, vmin, vmax):
plt.figure(figsize=(10, 10))
column_index = 35 # 指定特定列的数据
# 确保column_index在数组范围内
if column_index < 0 or column_index >= output.shape[1] or column_index >= target.shape[1]:
raise ValueError("column_index out of range")
# for y in range(output.shape[0]):
# pixel_value1 = output[y, column_index]
# pixel_value2 = target[y, column_index]
# pixel_values1.append(pixel_value1)
# pixel_values2.append(pixel_value2)
pixel_values1 = output[:, column_index] # 这里直接使用NumPy切片来提取列
pixel_values2 = target[:, column_index]
# 若vmin和vmax是给定的,可以使用它们来设置y轴的范围,也可以省略
if vmin is not None and vmax is not None:
plt.ylim(vmin, vmax)
plt.plot(pixel_values1, color='blue', linewidth=2, label='Prediction')
plt.plot(pixel_values2, color='red', linewidth=2, label='Ground Truth')
plt.legend(fontsize=20)
plt.xticks(fontsize=20) # 设置x轴刻度标签字体大小
plt.yticks(fontsize=20) # 设置y轴刻度标签字体大小
plt.xlabel('Vertical position (pixel index)', fontsize=20) # 修改x轴标签以反映实际情况
plt.ylabel('Velocity (m/s)', fontsize=20)
# 保存图片,确保目录存在或使用os.path.join来构建路径
plt.savefig(test_result_dir + 'PDD' + str(num) + '.png')
plt.close("all") # 关闭图形,释放资源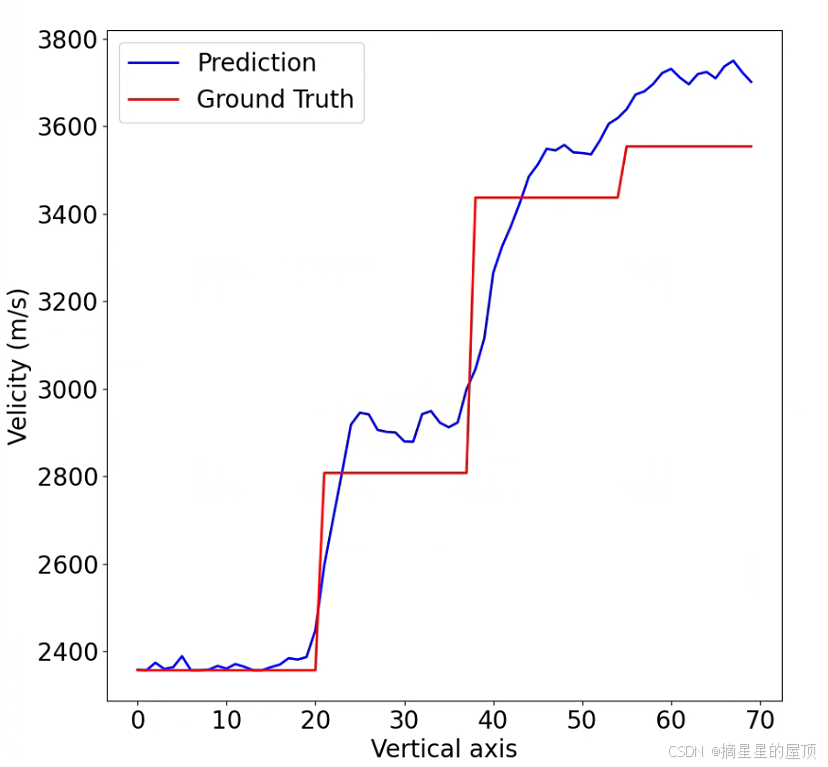
在上图显示了真实速度模型与预测速度模型的剖面图,那当有多个模型时如何在一张图片上显示呢?思考片刻后,认为可以设置一些全局变量,依次保存某一模型的预测值,最后生成即可。
2.2 吴恩达机器学习系列课程
2.2.1 介绍
这一小节主要介绍下述内容:
① 什么是机器学习,机器学习能做些什么事情;
② 什么是监督学习;
③ 什么是无监督学习;
2.2.1.1 机器学习
在机器学习的专业人士中,也不存在一个被广泛认可的定义来准确定义机器学习是什么或不是什么。因此,在下面通过一些人们尝试定义的案例来说明什么是机器学习。
第一个机器学习的定义来自于 Arthur Samuel,较为古老,且不太正式。他定义机器学习为:在进行特定编程的情况下,给予计算机学习能力的领域。Samuel 的定义可以回溯到 50 年代,他编写了一个西洋棋程序。这程序神 奇之处在于,编程者自己并不是个下棋高手。但因为他太菜了,于是就通过编程,让西洋棋程序自己跟自己下了上万盘棋。通过观察哪种布局(棋盘位置)会赢,哪种布局会输,久而久之,这西洋棋程序明白了什么是好的布局,什么样是坏的布局。然后程序通过一定数量的学习后,玩西洋棋的水平超过了 Samuel。 尽管编写者自己是个菜鸟,但因为计算机有着足够的耐心,去下上万盘的棋,没有人有这耐心去下这么多盘棋。通过这些练习,计算机获得无比丰富的经验,于是渐渐成为了比 Samuel 更厉害的西洋棋手。
第二个年代近一些的定义由Tom Mitchell提出,来自卡内基梅隆大学。Tom定义的机器学习是:一个好的学习问题定义如下,一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值 P,当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。我认为经验 E 就是程序上万次的自我练习的经验而任务 T 就是下棋。性能度量值 P 呢,就是它在与一 些新的对手比赛时,赢得比赛的概率。换句话说,以性能度量值 P 为标准,这个任务的性能,也就是这个任务 T 的系统性能,将在学习经验 E 后得到提高。
2.2.1.2 监督学习
目前存在几种不同类型的学习算法, 主要的两种类型被称之为监督学习和无监督学习。
监督学习:给学习算法一个数据集,该数据集中的每个样本都由相应的“正确答案”组成,然后再根据这些样本做出预测。(我们目前所接触的全波形反演就是监督学习:给定相应的地震数据与速度模型)
监督学习又分为回归问题与分类算法。
- 回归问题:试着通过回归推测出一系列连续值属性(一个连续的输出),预测输入变量与输出变量之间的关系。应用情况:房价预测;
- 分类算法:试着推测出离散的输出值(一组离散的结果)。应用情况:预测肿瘤的恶性与否、糖尿病;
在之后会介绍一种算法:支持向量机SVM——能让计算机处理无限多个特征。
2.2.1.3 无监督学习
无监督学习:在给定的数据集中没有任何的标签或者是有相同的标签或者就是没标签。
无监督学习一些类型介绍:
- 聚类算法:根据某个特定的标准对一个数据集中的数据进行划分,将其划分为不同的簇或类,使得同一个簇内的数据对象的相似性尽可能大,在不同簇内的数据对象的差异性也尽可能大。应用情况:新闻事件分类、基因组等
- 鸡尾酒宴问题:在计算机语音识别领域的一个问题,当前语音识别技术已经可以以较高精度识别一个人所讲的话,但是当说话的人数为两人或者多人时,语音识别率就会极大的降低,这一难题被称为鸡尾酒宴问题。
Octave是免费的开源软件,使用一个像 Octave 或 Matlab 的工具,许多学习算法变得只有几行代码就可实现。
2.2.2 单变量线性回归
2.2.2.1 模型表示
在本节课程中使用到的一些符号定义:
| 字符 | 代表意思 |
| 训练集中的实例数量 | |
| 特征/输入变量 | |
| 目标变量/输出变量 | |
| 训练集中的实例 | |
| 代表第 | |
| 学习算法的解决方案或函数也称为假设(hypothesis) |
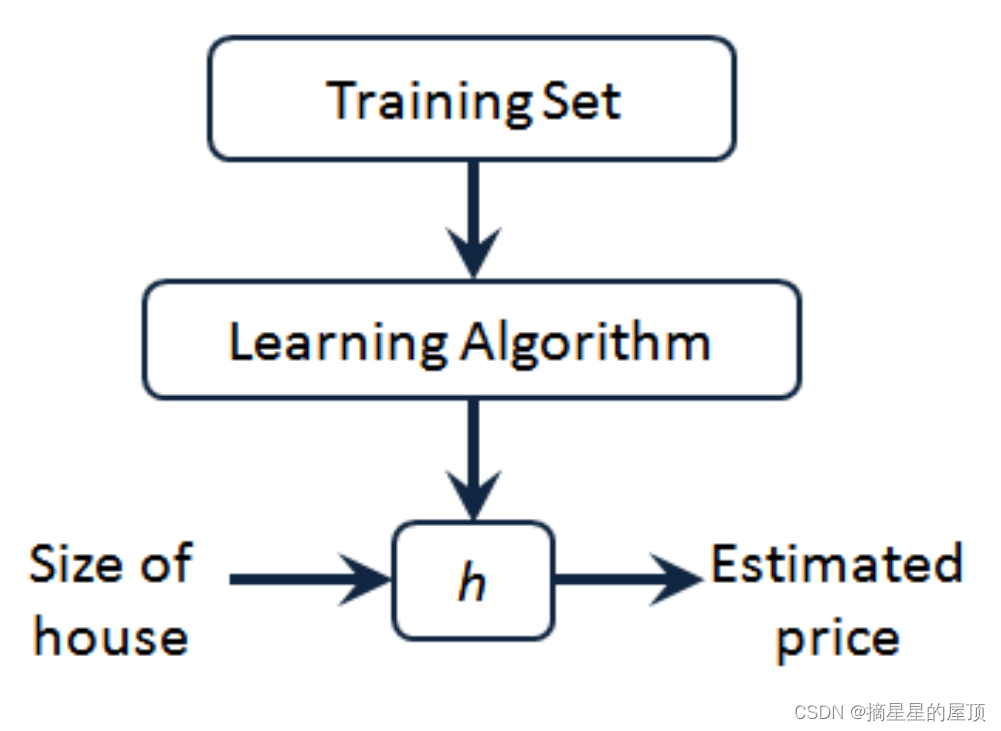
上图表示监督学习算法的工作方式。
单变量线性回归问题(只包含一个特征\输入变量):
2.2.2.2 代价函数
在上一小节定义了单变量线性回归问题,现在要做的是使模型选择合适的参数:使得得到的
值最小。代价函数如下:
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数对于大多数问题,特别是回归问题,都是一个合理的选择。还有其他的代价函数也能很好地发挥作用,但是平方误差代价函数可能是解决回归问题最常用的手段了。
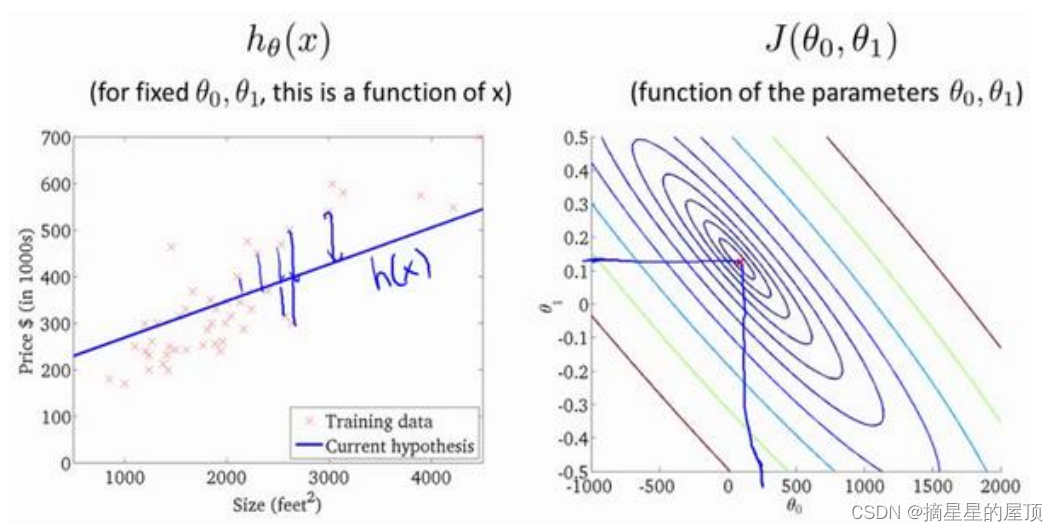
代价函数的直观理解如下:

可以将三维图转换为等高线图,这样更加直观:
2.2.2.3 梯度下降
梯度下降是一个用来求函数最小值的算法,将使用梯度下降算法来求出代价函数的最小值。
梯度下降背后的思想是:开始时会随机选择一个参数的组合,计算代 价函数,然后寻找下一个能让代价函数值下降最多的参数组合。持续这么做直到到到一个局部最小值(local minimum),因为并没有尝试完所有的参数组合,所以不能确定得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
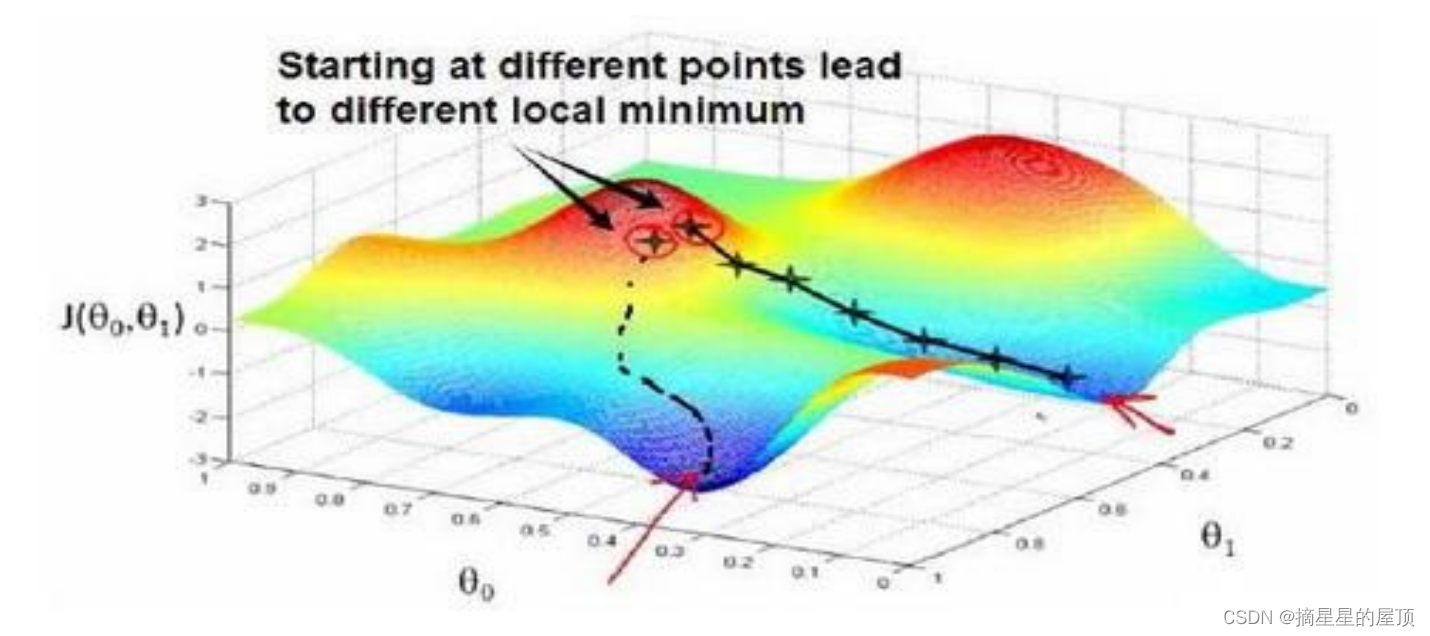
想象一下你正站立在山的这一点上,在梯度下降算法中,我们要做的就是旋转 360 度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你 会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并 决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。
批量梯度下降(batch gradient decent)算法的公式为:

其中,表示学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。对
赋值,使得
按照梯度下降最快方向进行,一直迭代下去,最终得到局部最小值。
在梯度下降中,需要更新,当
和
时,会产生更新。特别注意的是,这两个参数需要同时更新。当之后谈到梯度下降时,他们的意思就是同步更新。
- 如果学习率太小,需要很多步才能到达全局最低点。
- 如果学习率太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,下一次迭代又移 动了一大步,越过一次,又越过一次,一次次越过最低点,直到你发现实际上离最低点越来越远。它会导致无法收敛,甚至发散。
在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低时导数等于零,所以当我们接近局部最低时,导数值会自动变得越来越小,所以梯度下降将自动采取较小的幅度,这就是梯度下降的做法。所以实际上没有必要再另外减小学习率。
2.2.2.4 梯度下降的线性回归
梯度下降算法和线性回归算法的比较如下图所示:

算法被改写为:
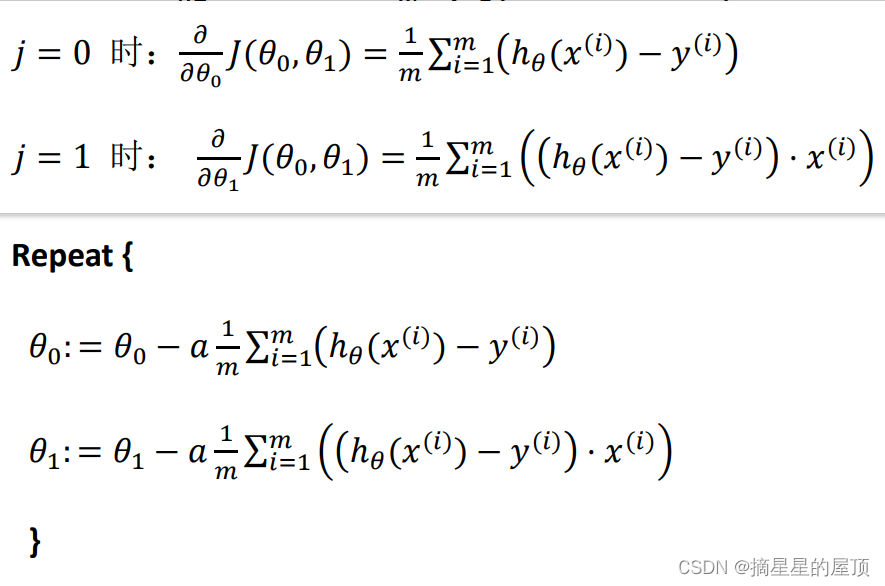
批量梯度下降: 指的是在梯度下降的每一步中都用到了所有的训练样本,在梯度下降中,在计算微分求导项时,需要进行求和运算,所以,在每一个单独的梯度下降中,最终都要计算这样一个东西,这个项需要对所有m个训练样 本求和。因此,批量梯度下降法这个名字说明了需要考虑所有这一"批"训练样本,而事实上,有时也有其他类型的梯度下降法,不是这种"批量"型的,不考虑整个的训练集,而是每次只关注训练集中的一些小的子集。
2.2.3 线性代数回顾
该节内容较为简单,回顾或者跳过均可。
2.2.3.1 向量和矩阵
下图是 4×2 矩阵,即 4 行 2 列,如m为行,n为列,那么m × n即 4×2:
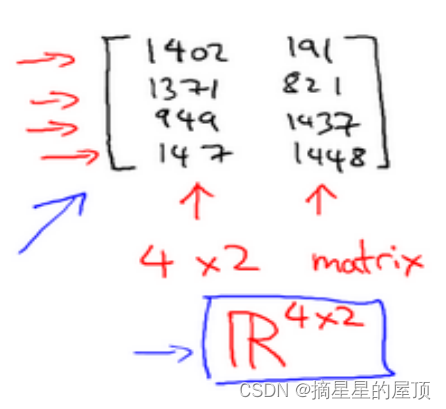
矩阵的维数=行数 x 列数,指的是第i行,第j列的元素。
向量是一种特殊的矩阵,在讲义中的向量一般都是列向量。
2.2.3.2 加法和标量乘法
- 矩阵的加法:行列数相等的可以加。
- 矩阵标量的乘法:每个元素都要乘。
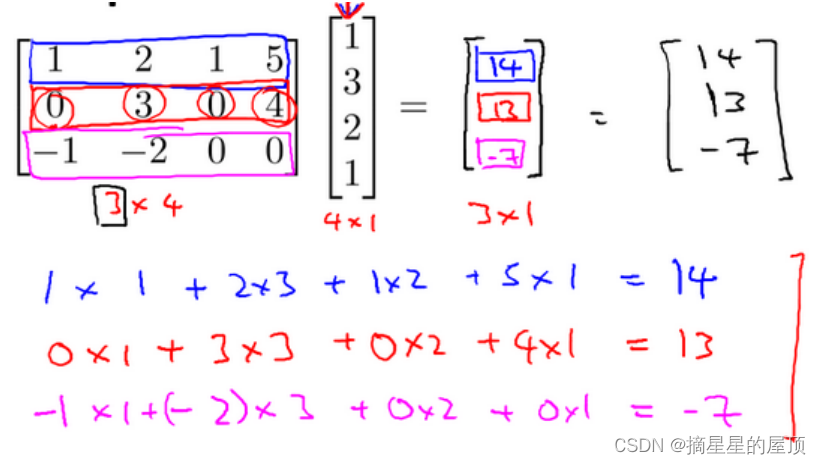
2.2.3.3 矩阵向量乘法
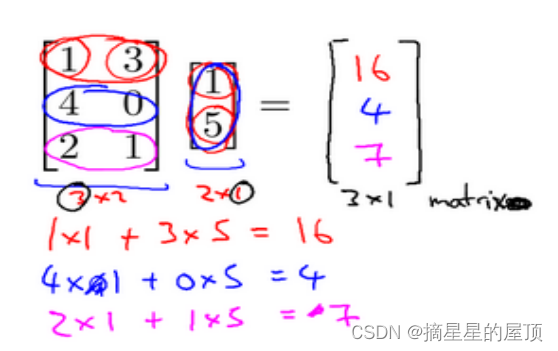
矩阵和向量的乘法如下图所示: 的矩阵乘以
的向量,得到
的向量。举例如下所示:
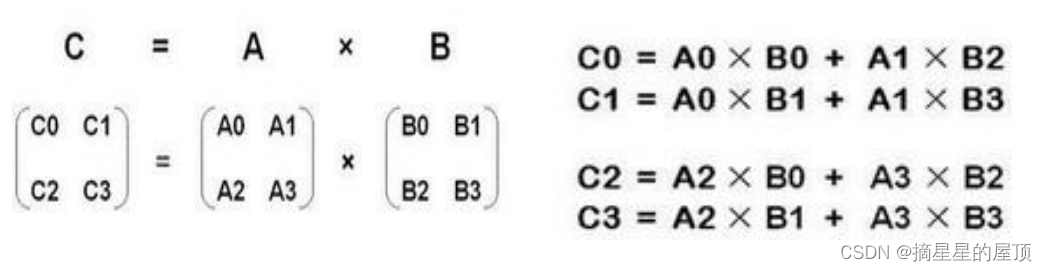
2.2.3.4 矩阵乘法与性质
矩阵乘法: 的矩阵乘以
的矩阵,变成
的矩阵。
矩阵乘法的性质:
- 矩阵的乘法不满足交换律:
;
- 矩阵的乘法满足结合律,即:
单位矩阵:在矩阵的乘法中,有一种矩阵起着特殊的作用,如同数的乘法中的1,我们称这种矩阵为单位矩阵.它是个方阵,一般用 或者
表示,本讲义都用
代表单位矩阵, 从左上角到右下角的对角线(称为主对角线)上的元素均为 1 以外全都为 0。如:
对于单位矩阵,有:。
2.2.3.5 逆与转置
矩阵的逆:如矩阵 是一个
矩阵(方阵),如果有逆矩阵,则:
。
一般在 OCTAVE 或者 MATLAB 中进行计算矩阵的逆矩阵。
矩阵的转置:设 为
阶矩阵(即
行
列),第
行
列的元素是
,即:
。
定义 的转置为这样一个
阶矩阵
,满足?
,即
(
的第
行第
列元素是
的第
行第
列元素),记
。(有些书记为
)。
直观来看,将 的所有元素绕着一条从第 1 行第 1 列元素出发的右下方 45 度的射线作 镜面反转,即得到
的转置。

矩阵的转置基本性质:
在matlab中矩阵转置:直接打一撇,即。
2.2.4 多变量线性回归
2.2.4.1 多维特征
在前面探讨了单变量\特征的回归模型,接着将对上述模型增加更多的特征,构成一个含有多个变量的模型,模型中的特征为:。增添更多特征后,引入一些新的符号注释:
| 符号 | 代表含义 |
| 特征的数量 | |
| 第 | |
| 特征矩阵中第 | |
| 代表支持多变量的假设 |
在上述公式中有 个参数和
个变量,引入
,此时模型中的参数和每一个训练实例都变成
维的向量,特征矩阵
的维度是
。
因此,公式可以简化为:。其中,上标
代表矩阵转置。
2.2.4.2 多变量梯度下降
与单变量线性回归类似,在多变量线性回归中,我们也构建一个代价函数,则这个代价 函数是所有建模误差的平方和,即:
其中:。
我们的目标和单变量线性回归问题中一样,是要找出使得代价函数最小的一系列参数。 多变量线性回归的批量梯度下降算法为:
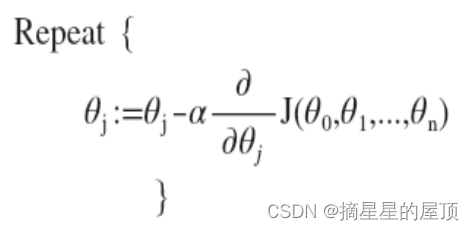
即:
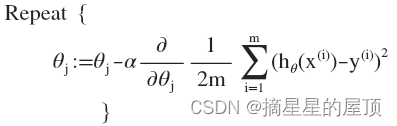
求导数后得到:

当时,
在开始的时候随机选择一系列的参数值,计算所有的预测结果后,再给所有的参数一个新的值,如此循环直到收敛。
2.2.4.3 特征缩放
在面对多维特征问题的时候,要保证这些特征都具有相近的尺度,这将帮助梯 度下降算法更快地收敛。
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0- 2000 平方英尺,而房间数量的值则是 0-5,以两个参数分别为横纵坐标,绘制代价函数的等 高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。
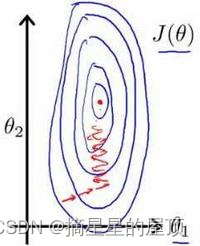
解决方案:将所有特征的尺度都尽量缩放到-1 到 1 之间。令,其中:
表示平均值,
表示标准差。
2.2.4.4 学习率
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同。因此,可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。也有一些自动测试是否收敛的方法,例如将代价函数的变化值与某个阀值(例如 0.001) 进行比较,但通常不选择这个方法。
梯度下降算法的每次迭代受到学习率的影响:
- 如果学习率
过小,则达到收敛所需的迭 代次数会非常高;
- 如果学习率
通常可以考虑下述学习率:
,数与数之间差不多3倍关系。
2.2.4.5 特征和多项式回归
当特征数量增多时,线性回归并不适用于所有数据。因此,有时我们需要曲线来适应我们的数据,如二次方模型:,或者三次方模型:
。
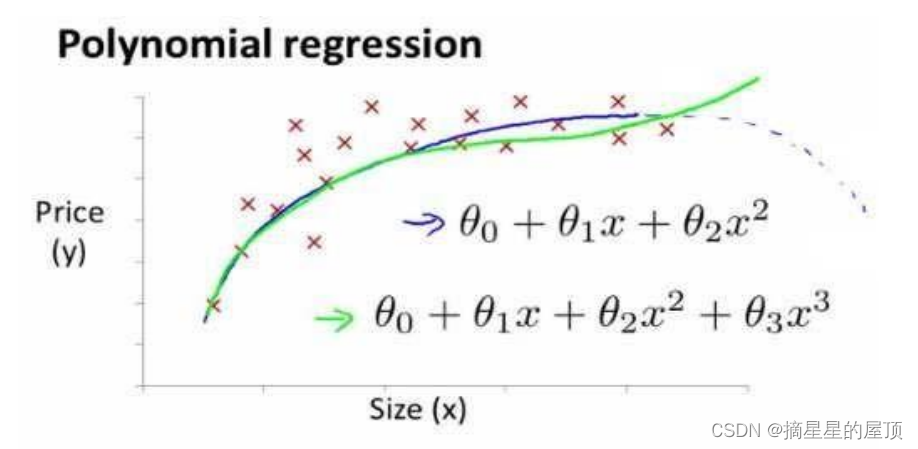
通常我们需要先观察数据然后再决定准备尝试怎样的模型。 另外,我们可以令: ,从而将模型转化为线性回归模型。还可以根据函数图像的特性,对模型进行调整,这一步需要很多经验。
注:如果采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。
2.2.4.6 正规方程
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的: 。 假设训练集特征矩阵为
(包含了
)并且训练集结果为向量
,则利 用正规方程解出向量
。
其中,上标 代表矩阵转置,上标- 1 代表矩阵的逆。设矩阵
,则:
。
注:对于那些不可逆的矩阵,正规方程方法是 不能用的。
(通常是因为特征之间不独立,如同时包含英尺为单位的尺寸和米为单位的尺寸两个特征,也有可能是特征数量大于训练集的数量,也可以理解为矩阵不满秩)
梯度下降与正规方程的比较如下:
| 梯 度下降 | 正规方程 | |
| 是否需要选择参数 | 需要选择学习率 | 不需要 |
| 迭代次数 | 需要多次迭代 | 一次运算得出 |
| 计算成本 | 当特征数量 | 需要计算 |
| 适用场景 | 适用于各种各类的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
只要特征变量的数目并不大,标准方程是一个很好的计算参数 的替代方法。 具体地说,只要特征变量数量小于一万,通常使用标准方程法,而不使用梯度下降法。 随着要讲的学习算法越来越复杂,例如,当我们讲到分类算法,像逻辑回归算法,实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法, 将不得不仍然使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。或者以后在课程中,会讲到的一些其他的算法,因为标准方程法不适合或者不能用在它们上。但对于这个特定的线性回归模型,标准方程法是一个 比梯度下降法更快的替代算法。所以,根据具体的问题具体分析。
正规方程的Python实现:
import numpy as np
def normalEqn(X, y):
theta = np.linalg.inv(X.T@X)@X.T@y #X.T@X 等价于 X.T.dot(X)
return theta三、下周计划
通过本周的学习对之前的一些知识理解更加深入,解决了之前的一些疑惑。
3.1 存在的问题
- 之前实验中使用的损失函数是MSE、MAE与交叉熵损失函数,如果写在论文中,算抄袭师兄的吗?
- 实验还没完成;
- 没有理解
是如何推导出来的,本周理解该推导过程。
3.2 计划
- 继续学习吴恩达机器学习视频;
- 继续完成实验与论文初稿;